Por qué el ADN de su marca es la base de su postura de seguridad
19
Jan 2022
19
Jan 2022
Descubra las vulnerabilidades que abren los activos basados en la web y cómo la IA puede ayudar a los equipos de seguridad a detectar los activos maliciosos y mantenerse seguros.
The internet is huge and is expanding every day. While this has many positives for businesses, managing the potential risks in this environment can be daunting. The reality is that across the internet brands are susceptible to everything from brand abuse to phishing websites. So, how is it possible that organisations can keep track of the web-based assets that belong to them, and at the same time distinguish them from something that may only look like it’s theirs? Finding and verifying all of a company’s web assets across the entire internet is a massive undertaking. You essentially need to filter the whole internet and try to pick out what is relevant, and then set about detecting the risks – or even potential risks – within what you have found.
This isn’t a process that can be managed manually. The staff-hours alone would make this hugely prohibitive, and that’s without taking into account the potential margin for error. Instead, it requires a different approach, one based around automation. At Darktrace, my team and I work on exactly those kind of solutions. We’ve developed our own algorithms to define what distinguishes a client’s brand-owned site from everything else on the internet. We refer to that as a company’s Brand DNA. These special characteristics help us to predict and identify where any brand-related assets are across the entire internet, and how they should be investigated further. The concept of an organisation’s Brand DNA breaks down into two areas: what is unique by design and what is uniqueby comparison.
Unique by Design
All brands have different design elements that help set them apart from other brands. This can be everything from their name and logo, to the different fonts and colours they use in all their communications and websites. By ingesting this data into our algorithms we are able to scan the internet for any web-based assets that may be relevant to a company, based on these key brand elements. While the elements of ‘unique by design’ are relatively easily understandable by humans, no organisations want to have their time taken up manually searching through millions of images every day in order to help them locate the web properties that might belong to their organisation.
Unique by Comparison
Conversely, ‘unique by comparison’ focuses more on the elements that a human would probably not be able to figure out by themselves. As we suggest potential new domains to customers, we build up a pool of assets. Automation allows us to find patterns in these assets that might not be immediately obvious to humans, such as elements of metadata,nameserver details, or even where a website is hosted. Although unique by design is more about what you actually see on a website and unique by comparison focuses on the back-end, in reality there are overlaps and the two things feed into each other.
As a very basic example: if a domain is hosted on nameserver where other company assets are hosted, AND the company logo is on the page, then the chances are this domain is a company-owned asset. In effect, the two approaches strengthen each other. By analysing all these details together, our algorithms can increasingly accurately score how likely an asset is to be owned by a company. I should add here that unique by comparison is based on comparing a lot of features at once, so it is often not as clear cut as the above example.
Combining Humans and AI
Ultimately, automating the process in this way helps to create a minimal-touch process for companies. The algorithms do all the filtering, enabling the creation of a much-reduced list of assets for the company to look through. Basically, we’re able to break down that list to avery small percentage of the internet that they actually need to look at and then analyse the risk those assets poseto the organisation.
We also use something which we internally label “AI2”(artificial intelligence with analyst interaction). This essentially means we’re adding a human layer to the automated process, for both input and output checks. While the algorithms do all the heavy lifting and aid scalability, the human element allows us to finetune or dive deeper into certain automated findings.
Detecting Malicious Assets
While the algorithms are principally focused on establishing a brand’s attack surface, a useful byproduct is that they can also locate malicious assets, such as potential phishing sites. For example, if something looks like it belongs to the customer, but doesn’t actually belong inside their directdigital infrastructure, then clearly there is an increased likelihood that it is either a brand abuse or phishing site.
On top of this, as part of our search process we can also automatically create combinations of possible URLs that cover common search errors such as typos or “fat finger”errors within brand names, and then hunt for those – clearly the likelihood of these URLs being rogue sites is greatly enhanced.
The Clearest View of the Attack Surface
By combining all these elements, companies are able to get the most complete view of their potential attack surface.And with the use of enhanced automation techniques they can do so with minimum effort. From this position companies are able to easily and quickly home in on the genuine items, and the areas that pose them the most risk. They can then use the resulting list to form the foundations from which they can apply the rest of their security strategy.
¿Te gusta esto y quieres más?
Reciba el último blog en su bandeja de entrada
Gracias. Hemos recibido su envío.
¡Ups! Algo salió mal al enviar el formulario.
NEWSLETTER
¿Te gusta esto y quieres más?
Stay up to date on the latest industry news and insights.
Darktrace son expertos de talla mundial en inteligencia de amenazas, caza de amenazas y respuesta a incidentes, y proporcionan apoyo al SOC las 24 horas del día a miles de clientes de Darktrace en todo el mundo. Inside the SOC está redactado exclusivamente por estos expertos y ofrece un análisis de los ciberincidentes y las tendencias de las amenazas, basado en la experiencia real sobre el terreno.
A Thorn in Attackers’ Sides: How Darktrace Uncovered a CACTUS Ransomware Infection
24
Apr 2024
What is CACTUS Ransomware?
In May 2023, Kroll Cyber Threat Intelligence Analysts identified CACTUS as a new ransomware strain that had been actively targeting large commercial organizations since March 2023 [1]. CACTUS ransomware gets its name from the filename of the ransom note, “cAcTuS.readme.txt”. Encrypted files are appended with the extension “.cts”, followed by a number which varies between attacks, e.g. “.cts1” and “.cts2”.
As the cyber threat landscape adapts to ever-present fast-paced technological change, ransomware affiliates are employing progressively sophisticated techniques to enter networks, evade detection and achieve their nefarious goals.
How does CACTUS Ransomware work?
In the case of CACTUS, threat actors have been seen gaining initial network access by exploiting Virtual Private Network (VPN) services. Once inside the network, they may conduct internal scanning using tools like SoftPerfect Network Scanner, and PowerShell commands to enumerate endpoints, identify user accounts, and ping remote endpoints. Persistence is maintained by the deployment of various remote access methods, including legitimate remote access tools like Splashtop, AnyDesk, and SuperOps RMM in order to evade detection, along with malicious tools like Cobalt Strike and Chisel. Such tools, as well as custom scripts like TotalExec, have been used to disable security software to distribute the ransomware binary. CACTUS ransomware is unique in that it adopts a double-extortion tactic, stealing data from target networks and then encrypting it on compromised systems [2].
At the end of November 2023, cybersecurity firm Arctic Wolf reported instances of CACTUS attacks exploiting vulnerabilities on the Windows version of the business analytics platform Qlik, specifically CVE-2023-41266, CVE-2023-41265, and CVE-2023-48365, to gain initial access to target networks [3]. The vulnerability tracked as CVE-2023-41266 can be exploited to generate anonymous sessions and perform HTTP requests to unauthorized endpoints, whilst CVE-2023-41265 does not require authentication and can be leveraged to elevate privileges and execute HTTP requests on the backend server that hosts the application [2].
Darktrace’s Coverage of CACTUS Ransomware
In November 2023, Darktrace observed malicious actors leveraging the aforementioned method of exploiting Qlik to gain access to the network of a customer in the US, more than a week before the vulnerability was reported by external researchers.
Here, Qlik vulnerabilities were successfully exploited, and a malicious executable (.exe) was detonated on the network, which was followed by network scanning and failed Kerberos login attempts. The attack culminated in the encryption of numerous files with extensions such as “.cts1”, and SMB writes of the ransom note “cAcTuS.readme.txt” to multiple internal devices, all of which was promptly identified by Darktrace DETECT™.
While traditional rules and signature-based detection tools may struggle to identify the malicious use of a legitimate business platform like Qlik, Darktrace’s Self-Learning AI was able to confidently identify anomalous use of the tool in a CACTUS ransomware attack by examining the rarity of the offending device’s surrounding activity and comparing it to the learned behavior of the device and its peers.
Unfortunately for the customer in this case, Darktrace RESPOND™ was not enabled in autonomous response mode during their encounter with CACTUS ransomware meaning that attackers were able to successfully escalate their attack to the point of ransomware detonation and file encryption. Had RESPOND been configured to autonomously act on any unusual activity, Darktrace could have prevented the attack from progressing, stopping the download of any harmful files, or the encryption of legitimate ones.
Cactus Ransomware Attack Overview
Holiday periods have increasingly become one of the favoured times for malicious actors to launch their attacks, as they can take advantage of the festive downtime of organizations and their security teams, and the typically more relaxed mindset of employees during this period [4].
Following this trend, in late November 2023, Darktrace began detecting anomalous connections on the network of a customer in the US, which presented multiple indicators of compromise (IoCs) and tactics, techniques and procedures (TTPs) associated with CACTUS ransomware. The threat actors in this case set their attack in motion by exploiting the Qlik vulnerabilities on one of the customer’s critical servers.
Darktrace observed the server device making beaconing connections to the endpoint “zohoservice[.]net” (IP address: 45.61.147.176) over the course of three days. This endpoint is known to host a malicious payload, namely a .zip file containing the command line connection tool PuttyLink [5].
Darktrace’s Cyber AI Analyst was able to autonomously identify over 1,000 beaconing connections taking place on the customer’s network and group them together, in this case joining the dots in an ongoing ransomware attack. AI Analyst recognized that these repeated connections to highly suspicious locations were indicative of malicious command-and-control (C2) activity.
Figure 1: Cyber AI Analyst Incident Log showing the offending device making over 1,000 connections to the suspicious hostname “zohoservice[.]net” over port 8383, within a specific period.
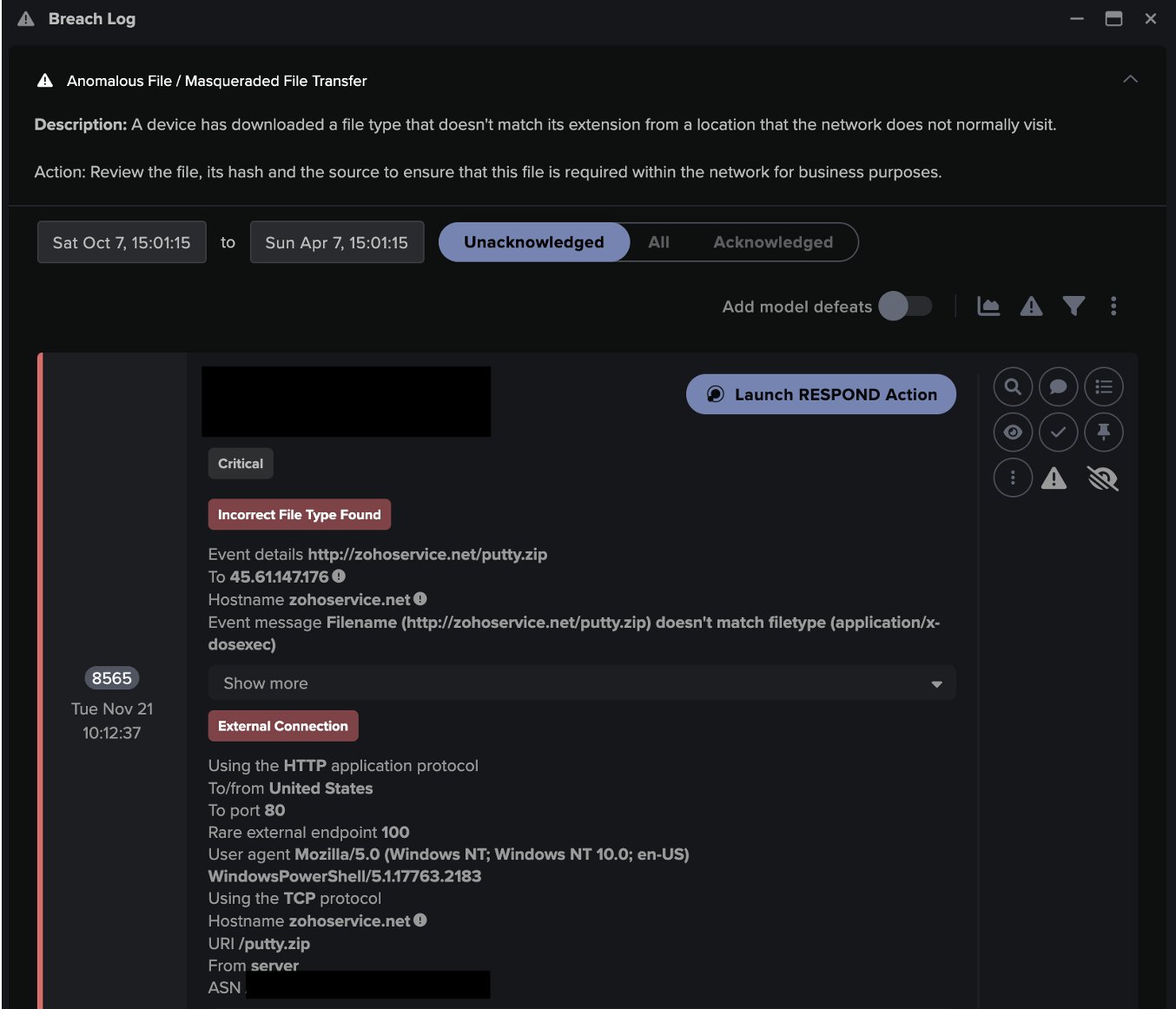
The infected device was then observed downloading the file “putty.zip” over a HTTP connection using a PowerShell user agent. Despite being labelled as a .zip file, Darktrace’s detection capabilities were able to identify this as a masqueraded PuttyLink executable file. This activity resulted in multiple Darktrace DETECT models being triggered. These models are designed to look for suspicious file downloads from endpoints not usually visited by devices on the network, and files whose types are masqueraded, as well as the anomalous use of PowerShell. This behavior resembled previously observed activity with regards to the exploitation of Qlik Sense as an intrusion technique prior to the deployment of CACTUS ransomware [5].
Figure 2: The downloaded file’s URI highlighting that the file type (.exe) does not match the file's extension (.zip). Information about the observed PowerShell user agent is also featured.
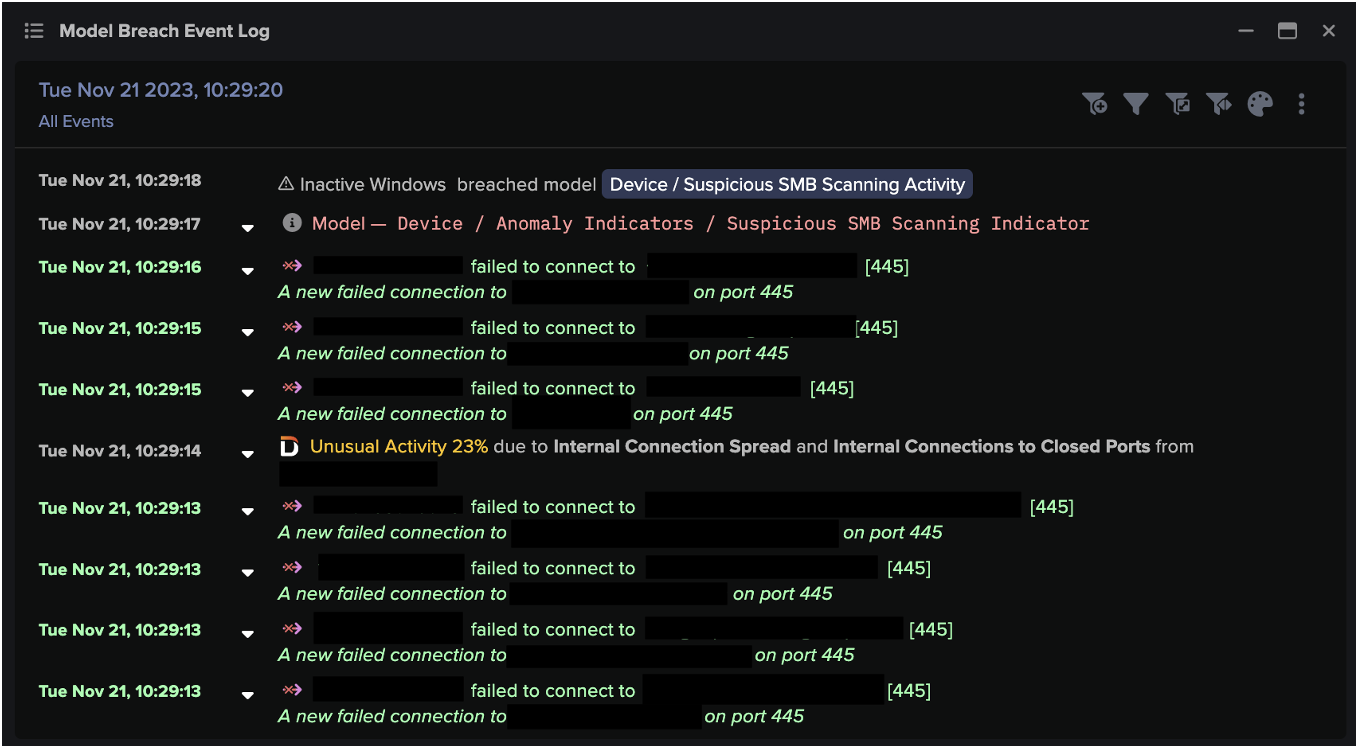
Following the download of the masqueraded file, Darktrace observed the initial infected device engaging in unusual network scanning activity over the SMB, RDP and LDAP protocols. During this activity, the credential, “service_qlik” was observed, further indicating that Qlik was exploited by threat actors attempting to evade detection. Connections to other internal devices were made as part of this scanning activity as the attackers attempted to move laterally across the network.
Figure 3: Numerous failed connections from the affected server to multiple other internal devices over port 445, indicating SMB scanning activity.
The compromised server was then seen initiating multiple sessions over the RDP protocol to another device on the customer’s network, namely an internal DNS server. External researchers had previously observed this technique in CACTUS ransomware attacks where an RDP tunnel was established via Plink [5].
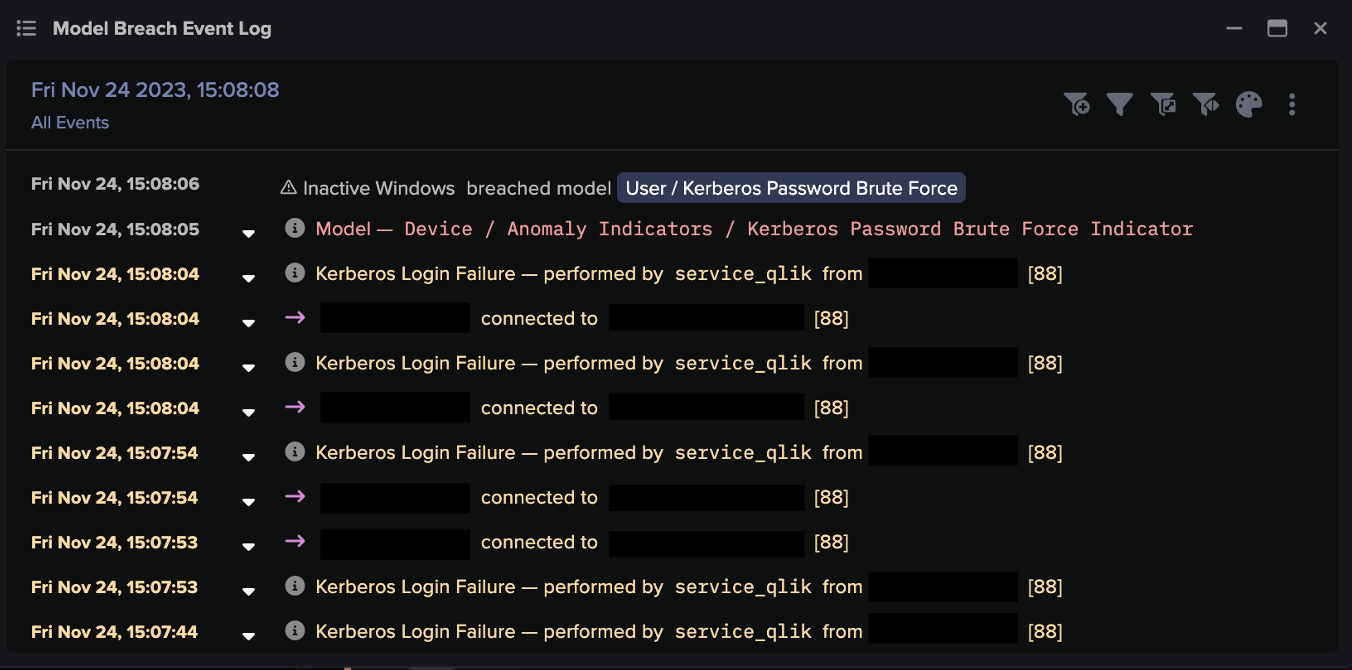
A few days later, on November 24, Darktrace identified over 20,000 failed Kerberos authentication attempts for the username “service_qlik” being made to the internal DNS server, clearly representing a brute-force login attack. There is currently a lack of open-source intelligence (OSINT) material definitively listing Kerberos login failures as part of a CACTUS ransomware attack that exploits the Qlik vulnerabilities. This highlights Darktrace’s ability to identify ongoing threats amongst unusual network activity without relying on existing threat intelligence, emphasizing its advantage over traditional security detection tools.
Figure 4: Kerberos login failures being carried out by the initial infected device. The destination device detected was an internal DNS server.
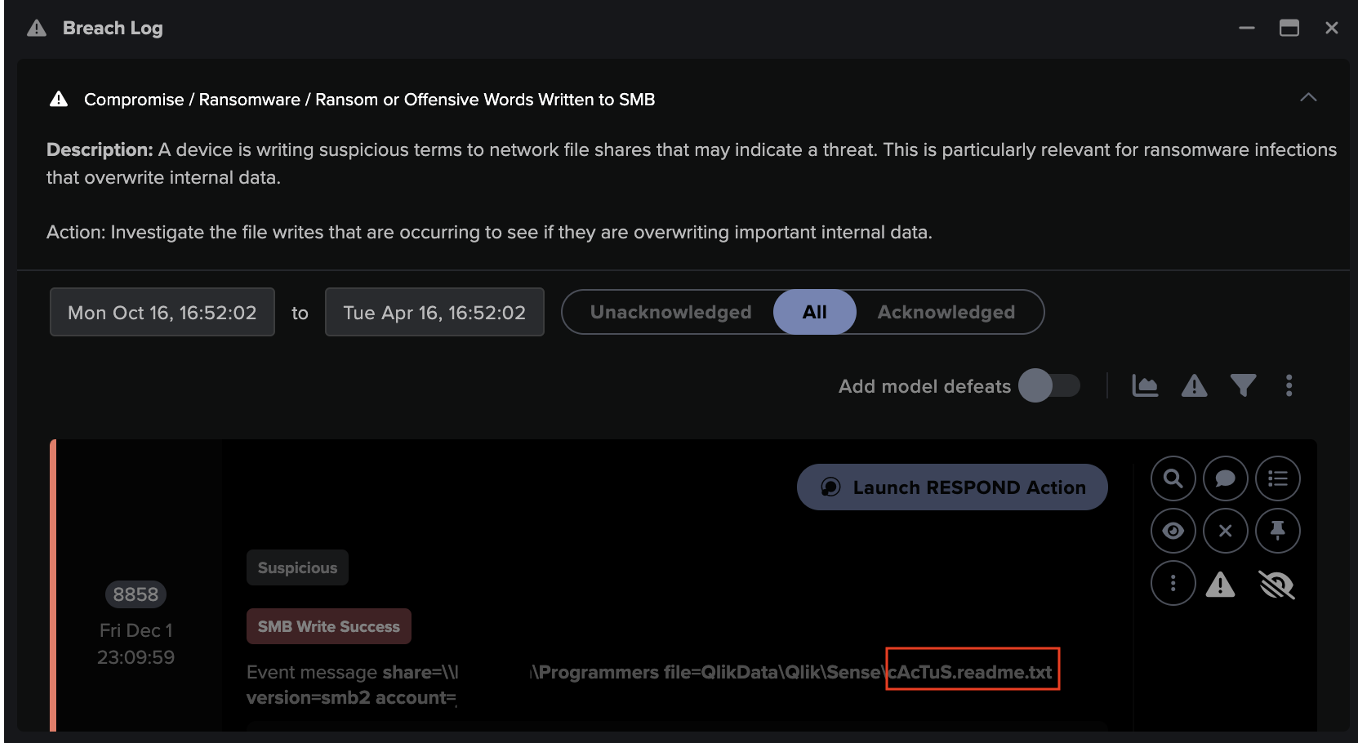
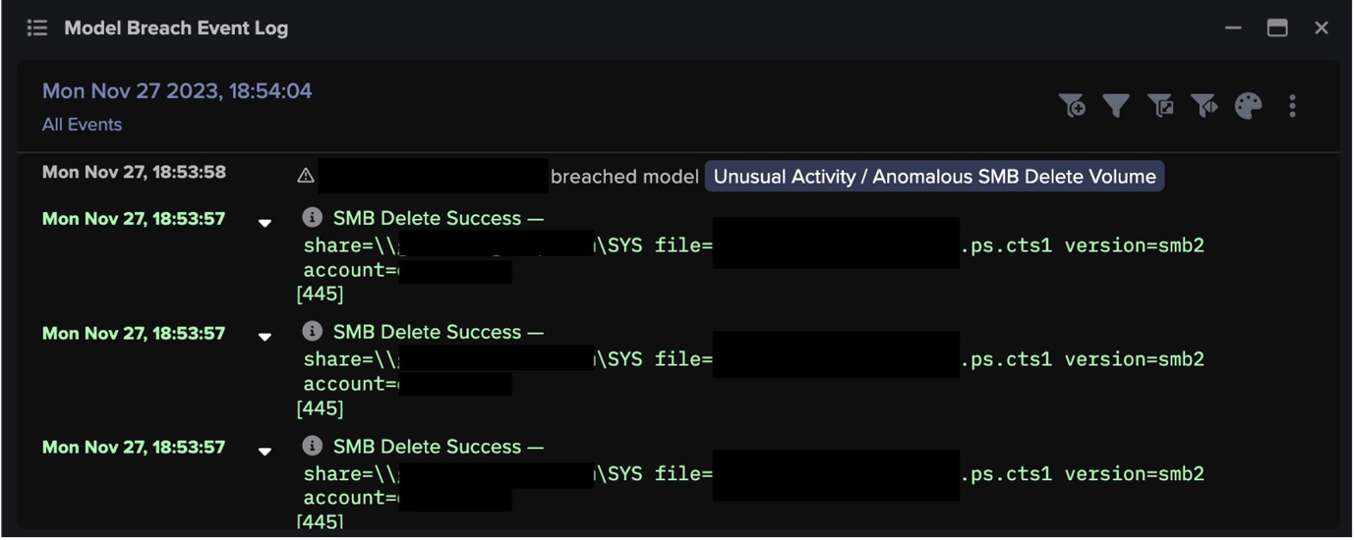
In the month following these failed Kerberos login attempts, between November 26 and December 22, Darktrace observed multiple internal devices encrypting files within the customer’s environment with the extensions “.cts1” and “.cts7”. Devices were also seen writing ransom notes with the file name “cAcTuS.readme.txt” to two additional internal devices, as well as files likely associated with Qlik, such as “QlikSense.pdf”. This activity detected by Darktrace confirmed the presence of a CACTUS ransomware infection that was spreading across the customer’s network.
Figure 5: The model, 'Ransom or Offensive Words Written to SMB', triggered in response to SMB file writes of the ransom note, ‘cAcTuS.readme.txt’, that was observed on the customer’s network.
Figure 6: CACTUS ransomware extensions, “.cts1” and “.cts7”, being appended to files on the customer’s network.
Following this initial encryption activity, two affected devices were observed attempting to remove evidence of this activity by deleting the encrypted files.
Figure 7: Attackers attempting to remove evidence of their activity by deleting files with appendage “.cts1”.
Conclusion
In the face of this CACTUS ransomware attack, Darktrace’s anomaly-based approach to threat detection enabled it to quickly identify multiple stages of the cyber kill chain occurring in the customer’s environment. These stages ranged from ‘initial access’ by exploiting Qlik vulnerabilities, which Darktrace was able to detect before the method had been reported by external researchers, to ‘actions on objectives’ by encrypting files. Darktrace’s Self-Learning AI was also able to detect a previously unreported stage of the attack: multiple Kerberos brute force login attempts.
If Darktrace’s autonomous response capability, RESPOND, had been active and enabled in autonomous response mode at the time of this attack, it would have been able to take swift mitigative action to shut down such suspicious activity as soon as it was identified by DETECT, effectively containing the ransomware attack at the earliest possible stage.
Learning a network’s ‘normal’ to identify deviations from established patterns of behaviour enables Darktrace’s identify a potential compromise, even one that uses common and often legitimately used administrative tools. This allows Darktrace to stay one step ahead of the increasingly sophisticated TTPs used by ransomware actors.
Credit to Tiana Kelly, Cyber Analyst & Analyst Team Lead, Anna Gilbertson, Cyber Analyst
The State of AI in Cybersecurity: How AI will impact the cyber threat landscape in 2024
22
Apr 2024
About the AI Cybersecurity Report
We surveyed 1,800 CISOs, security leaders, administrators, and practitioners from industries around the globe. Our research was conducted to understand how the adoption of new AI-powered offensive and defensive cybersecurity technologies are being managed by organizations.
Are organizations feeling the impact of AI-powered cyber threats?
Nearly three-quarters (74%) state AI-powered threats are now a significant issue. Almost nine in ten (89%) agree that AI-powered threats will remain a major challenge into the foreseeable future, not just for the next one to two years.
However, only a slight majority (56%) thought AI-powered threats were a separate issue from traditional/non AI-powered threats. This could be the case because there are few, if any, reliable methods to determine whether an attack is AI-powered.
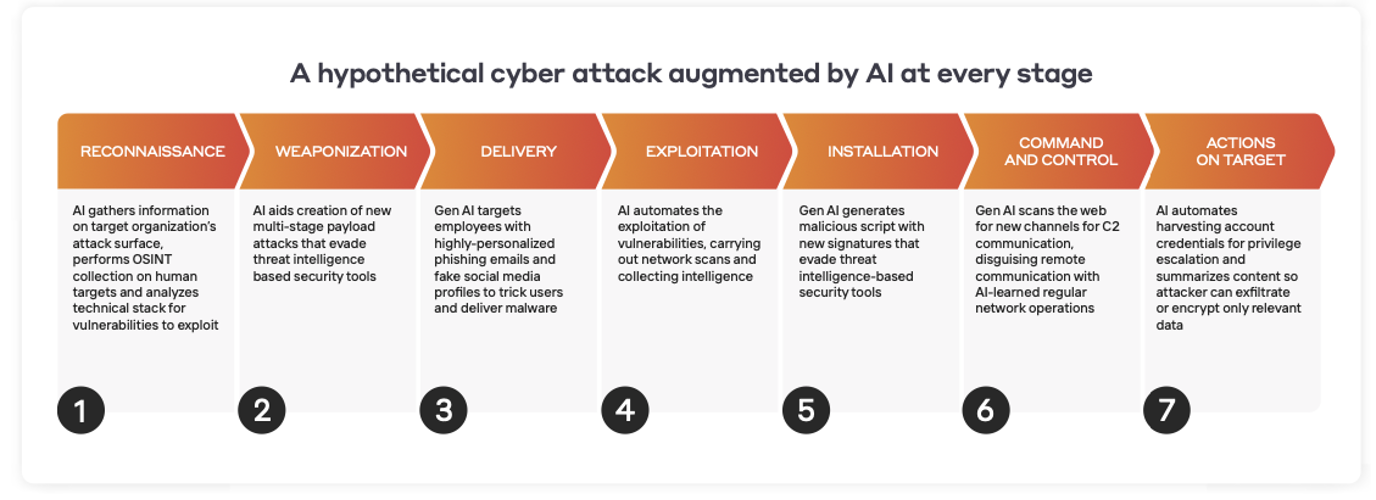
Identifying exactly when and where AI is being applied may not ever be possible. However, it is possible for AI to affect every stage of the attack lifecycle. As such, defenders will likely need to focus on preparing for a world where threats are unique and are coming faster than ever before.
Are security stakeholders concerned about AI’s impact on cyber threats and risks?
The results from our survey showed that security practitioners are concerned that AI will impact organizations in a variety of ways. There was equal concern associated across the board – from volume and sophistication of malware to internal risks like leakage of proprietary information from employees using generative AI tools.
What this tells us is that defenders need to prepare for a greater volume of sophisticated attacks and balance this with a focus on cyber hygiene to manage internal risks.
One example of a growing internal risks is shadow AI. It takes little effort for employees to adopt publicly-available text-based generative AI systems to increase their productivity. This opens the door to “shadow AI”, which is the use of popular AI tools without organizational approval or oversight. Resulting security risks such as inadvertent exposure of sensitive information or intellectual property are an ever-growing concern.
Are organizations taking strides to reduce risks associated with adoption of AI in their application and computing environment?
71.2% of survey participants say their organization has taken steps specifically to reduce the risk of using AI within its application and computing environment.
16.3% of survey participants claim their organization has not taken these steps.
These findings are good news. Even as enterprises compete to get as much value from AI as they can, as quickly as possible, they’re tempering their eager embrace of new tools with sensible caution.
Still, responses varied across roles. Security analysts, operators, administrators, and incident responders are less likely to have said their organizations had taken AI risk mitigation steps than respondents in other roles. In fact, 79% of executives said steps had been taken, and only 54% of respondents in hands-on roles agreed. It seems that leaders believe their organizations are taking the needed steps, but practitioners are seeing a gap.
Do security professionals feel confident in their preparedness for the next generation of threats?
A majority of respondents (six out of every ten) believe their organizations are inadequately prepared to face the next generation of AI-powered threats.
The survey findings reveal contrasting perceptions of organizational preparedness for cybersecurity threats across different regions and job roles. Security administrators, due to their hands-on experience, express the highest level of skepticism, with 72% feeling their organizations are inadequately prepared. Notably, respondents in mid-sized organizations feel the least prepared, while those in the largest companies feel the most prepared.
Regionally, participants in Asia-Pacific are most likely to believe their organizations are unprepared, while those in Latin America feel the most prepared. This aligns with the observation that Asia-Pacific has been the most impacted region by cybersecurity threats in recent years, according to the IBM X-Force Threat Intelligence Index.
The optimism among Latin American respondents could be attributed to lower threat volumes experienced in the region, but it's cautioned that this could change suddenly (1).
What are biggest barriers to defending against AI-powered threats?
The top-ranked inhibitors center on knowledge and personnel. However, issues are alluded to almost equally across the board including concerns around budget, tool integration, lack of attention to AI-powered threats, and poor cyber hygiene.
The cybersecurity industry is facing a significant shortage of skilled professionals, with a global deficit of approximately 4 million experts (2). As organizations struggle to manage their security tools and alerts, the challenge intensifies with the increasing adoption of AI by attackers. This shift has altered the demands on security teams, requiring practitioners to possess broad and deep knowledge across rapidly evolving solution stacks.
Educating end users about AI-driven defenses becomes paramount as organizations grapple with the shortage of professionals proficient in managing AI-powered security tools. Operationalizing machine learning models for effectiveness and accuracy emerges as a crucial skill set in high demand. However, our survey highlights a concerning lack of understanding among cybersecurity professionals regarding AI-driven threats and the use of AI-driven countermeasures indicating a gap in keeping pace with evolving attacker tactics.
The integration of security solutions remains a notable problem, hindering effective defense strategies. While budget constraints are not a primary inhibitor, organizations must prioritize addressing these challenges to bolster their cybersecurity posture. It's imperative for stakeholders to recognize the importance of investing in skilled professionals and integrated security solutions to mitigate emerging threats effectively.
1. IBM, X-Force Threat Intelligence Index 2024, Available at: https://www.ibm.com/downloads/cas/L0GKXDWJ
2. ISC2, Cybersecurity Workforce Study 2023, Available at: https://media.isc2.org/-/media/Project/ISC2/Main/Media/ documents/research/ISC2_Cybersecurity_Workforce_Study_2023.pdf?rev=28b46de71ce24e6ab7705f6e3da8637e









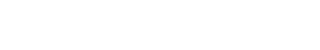





















![Cyber AI Analyst Incident Log showing the offending device making over 1,000 connections to the suspicious hostname “zohoservice[.]net” over port 8383, within a specific period.](https://assets-global.website-files.com/626ff4d25aca2edf4325ff97/662971c1cf09890fd46729a1_Screenshot%202024-04-24%20at%201.55.10%20PM.png)